Diagrams of linear regression
I made a big diagram describing some assumptions (MLR1-6) that are used in linear regression. In my diagram, there are categories (in rectangles with dotted lines) of mathematical facts that follow from different subsets of MLR1-6. References in brackets are to Hayashi (2000).
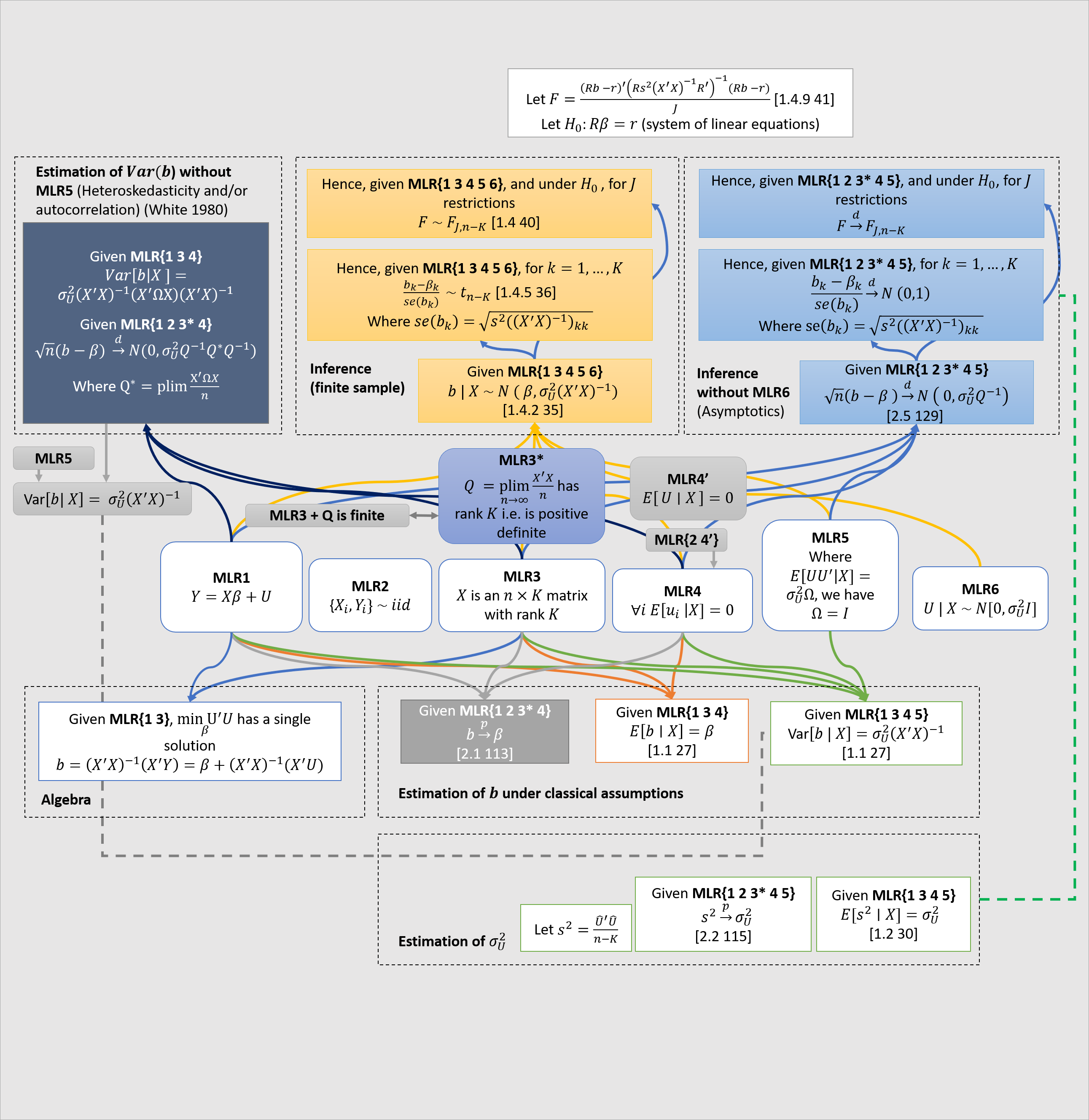
A couple of comments about the diagram are in order.
- , are a vectors of random variables. may contain numbers or random variables. is a vector of numbers.
- We measure: realisations of , (realisations of) . We do not measure: , . We have one equation and two unknowns: we need additional assumptions on .
- We make a set of assumptions (MLR1-6) about the joint distribution . These assumptions imply some theorems relating the distribution of and the distribution of .
- In the diagram, I stick to the brute mathematics, which is entirely independent of its (causal) interpretation.1
- Note the difference between MLR4 and MLR4’. The point of using the stronger MLR4 is that, in some cases, provided MLR4, MLR2 is not needed. To prove unbiasedness, we don’t need MLR2. For finite sample inference, we also don’t need MLR2. But whenever the law of large numbers is involved, we do need MLR2 as a standalone condition. Note also that, since MLR2 and MLR4’ together imply MLR4, clearly MLR2 and MLR4 are never both needed. But I follow standard practise (e.g. Hayashi) in including them both, for example in the asymptotic inference theorems.
- Note that since is a symmetric square matrix, has full rank iff is positive definite; these are equivalent statements (see Wooldridge 2010 p. 57). Furthermore, if has full rank , then has full rank , so MLR3* is equivalent to MLR3 plus the fact that is finite (i.e actually converges).
- Note that given MLR2 and the law of large numbers, could alternatively be written
- Note that whenever I write a and set it equal to some matrix, I am assuming the matrix is finite. Some treatments will explicitly say is finite, but I omit this.
- Note that by the magic of matrix inversion, . 2
- Note that these expressions are equal: . Seeing this helps with intuition.
The second diagram gives the asymptotic distribution of the IV and 2SLS estimators.3
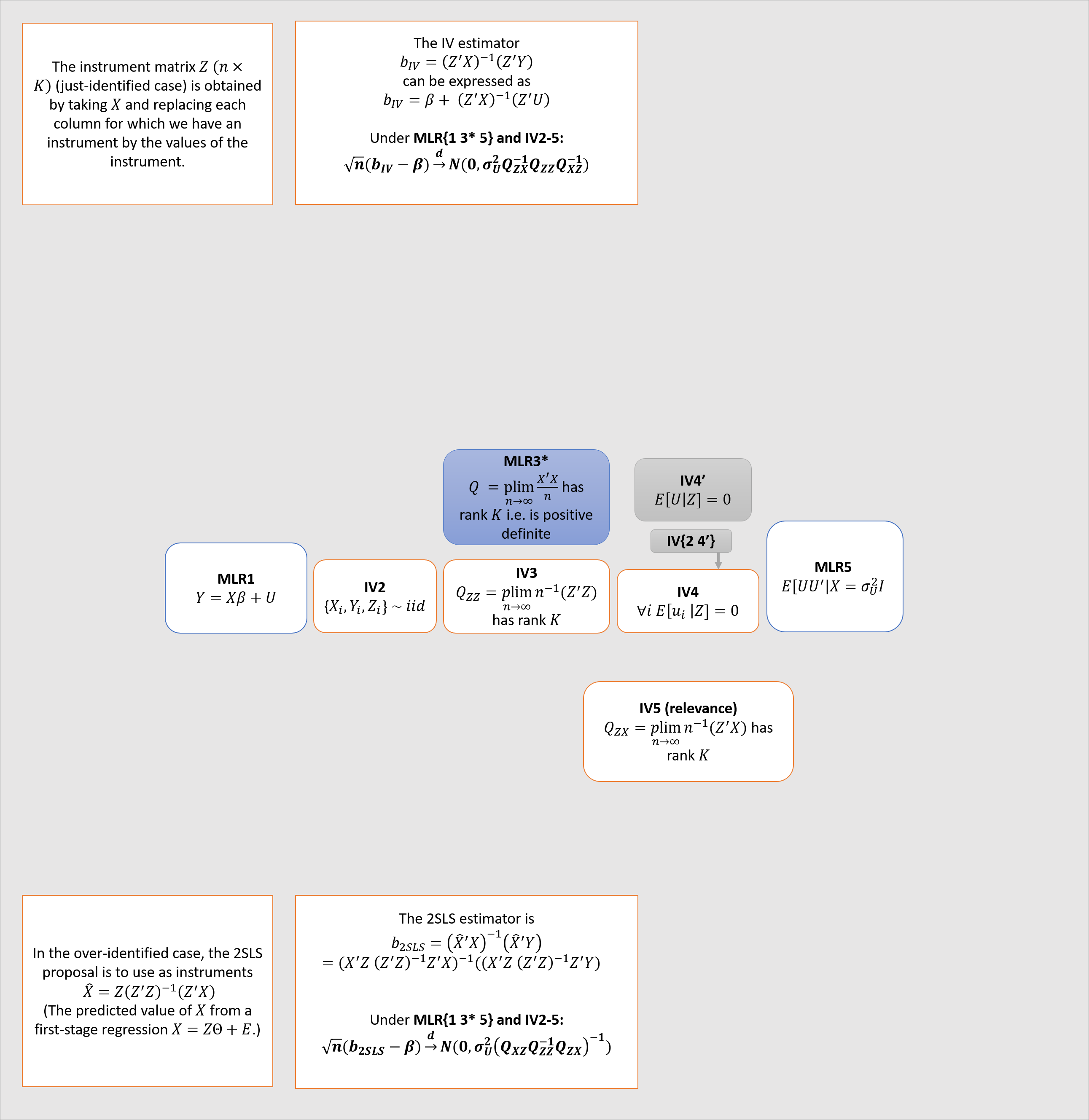
I made this is PowerPoint, not knowing how to do it better. Here is the file.
-
But of course what really matters is the causal interpretation.
As Pearl (2009) writes, “behind every causal claim there must lie some causal assumption that is not discernible from the joint distribution and, hence, not testable in observational studies”. If we wish to interpret (and hence ) causally, we must interpret MLR4 causally; it becomes a (strong) causal assumption.
As far as I can tell, when econometricians give a causal interpretation it is typically done thus (they are rarely explicit about it):
- MLR1 holds in every possible world (alternatively: it specifies not just actual, but all potential outcomes), hence is unobservable even in principle.
- yet we make assumption MLR4 about
This talk of the distribution of a fundamentally unobservable “variable” is a confusing device. Pearl’s method is more explicit: replace MLR with the causal graph below, where is used to make it extra clear that the causation only runs one way. MLR1 corresponds to the expression for (and, redundantly, the two arrows towards ), MLR4 corresponds to the absence of arrows connecting and . We thus avoid “hiding causal assumptions under the guise of latent variables” (Pearl). (Because of the confusing device, econometricians, to put it kindly, don’t always sharply distinguish the mathematics of the diagram from its (causal) interpretation.)
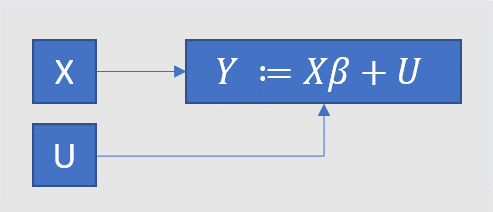
-
Think about it! This seems intuitive when you don’t think about it, mysterious when you think about it a little, and presumably becomes obvious again if you really understand matrix algebra. I haven’t reached the third stage. ↩
-
For IV, it’s even clearer that the only reason to care is the causal interpretation. But I follow good econometrics practice and make only mathematical claims. ↩
